

拓元智慧创始人林倞:ChatGPT背后的技术思考
ChatGPT ,再度引燃了大众与商界对于科技的终极畅想
ChatGPT ,再度引燃了大众与商界对于科技的终极畅想。这款被用于文本生成等自然语言处理任务的聊天机器人,成为全球各地新闻的主角,展示着人类在人工智能应用能够实现商业化的最终可能性。
而在狂欢之外,更多人开始思考,基于云计算与AI人工智能的科技未来,是否已经迎来技术拐点?不久前,英伟达CEO黄仁勋也在公开活动中表示:“ChatGPT是人工智能领域的iPhone时刻。”
从论坛Reddit的情况来看,相比于最开始的尝鲜和玩票性质,现在每天都有几十个基于OpenAI的新产品上线,在寻找着未来。再次升级的 GPT-4,更是让这股浪潮波涌。
ChatGPT背后的技术,到底代表着什么?新的技术周期是否已经到来?基于OpenAI的商业场景又会在哪里率先落地?中山大学教授、拓元智慧创始人林倞展示了他的思考。一个前置的观点是,作为自主研究实践多模态认知AI技术并进行商业化落地的创业者,在他的视野里,ChatGPT更多的,是为大众打开认知的大门。
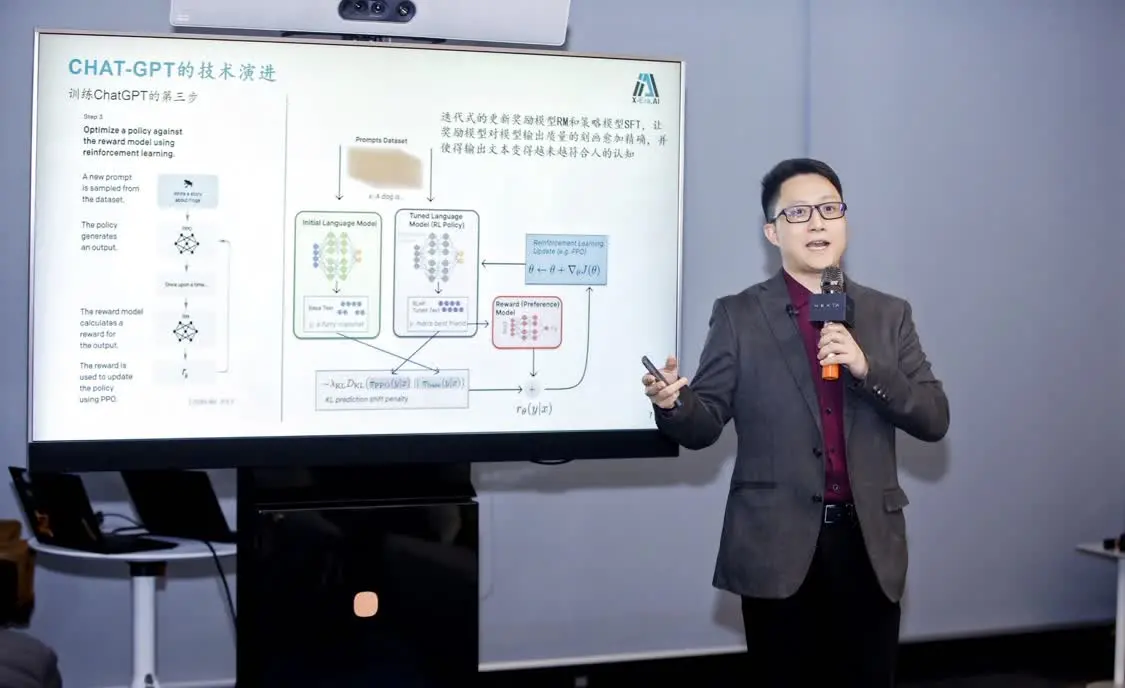
中山大学教授、拓元智慧创始人林倞
一.ChatGPT,浪潮如何兴起
“ChatGPT诞生的意义,不亚于互联网的诞生。”比尔盖茨的断言,有多少是因为微软与OpenAI之间复杂的关系,我们不得而知。但风平浪静已久的互联网圈,少有的掀起一场大众式热潮。
GPT即Generative Pre-trained Transformer(生成式预训练Transformer)的缩写。从定义来说,GPT的技术定义,是一种自然语言处理模型,使用多层变换器来预测下一个单词的概率分布,通过训练在大型文本语料库上学习到的语言模式来生成自然语言文本,从 GPT-1 到 GPT-3 智能化程度不断提升,而ChatGPT 则是基于GPT3.5架构开发的对话AI应用。
简单叙述GPT发展路径的技术特点,GPT-3直接带火了“提示学习”这一技术范式(prompt),而InstructGPT、ChatGPT这类基于GPT-3.5的模型特点,则是结合监督学习与强化学习,加入了人类反馈强化学习,将人类期待的结果反馈给模型,后者额外增加了微调的安全机制。
真正引爆大众关注的技术内核,是从GPT-3到GPT-3.5的演化,核心就在于引入了training on code及引导性微调。人类所打造的代码,无论是Java抑或Python,都存在强逻辑性与一致性。AI模型需要在代码上预训练,进行逻辑能力的强化。
这一过程中,升级的重点,一是用code代码引入人类定义好的task任务,并提供更为符合人机对话需求的训练,最终有了ChatGPT的实际应用。
不久前,GPT-4.0的出现,更是让这股浪潮愈发汹涌。
二.GPT-4.0,未来的一块基石
理解ChatGPT,可以从其训练步骤开始。从收集示范数据、训练监督政策到收集比较数据、训练奖励模型,进行策略优化,三个核心步骤的不断训练之下,模型迭代后所产出的文本自然越来越精准。
具体来说,第一步,利用人类的标注数据,对GPT进行有监督训练,主要迭代内容为模型中的输出策略部分(即SFT模型)。第二步,则是依据人类的打分标准训练出一个奖励模型RM。第三步,迭代式的更新奖励模型RM与策略模型SFT,使得模型输出质量的刻画愈发精准,最终让输出信息愈发符合人类的认知。
“不要抱有太大的期待。”林倞个人的观点是,因为应急能力问题的存在,目前ChatGPT还不是无所不能。必须认识到它的优缺点都十分鲜明。
在真实性与逻辑性上无法保证确定性,甚至同样提示词多次提问所收获的答案都存在差异,存在一本正经的胡说八道情况。道德与伦理上的风险问题也存在隐患。
除此以外,ChatGPT所面临的一大问题,是如何持续性更新领域知识。投喂型而非自主型的训练方式,新领域内容的更新,取决于示范数据的更新。在数据安全与部署成本的双维压力下,可持续性依旧存疑。
“大部分人无需担心工作会被取代。”林倞认为,ChatGPT的本质依旧是被造出来的“轮子”,是对人类生产效率的提升,在目前可预见的应用中,其对各类重复工作的效率提升作用巨大。
而GPT-4的出现,又为生成式预训练的可能性,添加了一份方向性的确定。其最为人乐道的,是对于视频、图片的理解,或者说对于用户意图理解的延伸。在应用层的热点,就是已经成为一种风尚的AI作画。
Runway AI、Midjourney、Novel AI的百花齐放,背后是DDPM、Stable Diffusion(开源)等文本图像、文本视频生成等技术的不断演进。为此,林倞举例了几种算法技术核心概念,以及演变方向。
以Diffusion Model为例。其算法理论是在信息推理时给定一个噪音信号作为输入,以训练模型估计高斯噪声,以前者减去后者,循环重复直至恢复原始信号,理论上可以实现语音、图像、超分辨率等连续信号的生成。
从模型类型区分,Diffusion Model属于一种自回归模型,需要反复迭代计算,训练和推理成本高昂。而Latent Diffusion model(即LDM)在此基础上做了迭代,把Diffusion过程改为在Latent Space中进行在计算复杂程度实现优化,最终实现可以生成高分辨率图像。
LDM的价值在于,提出了以cross-attention的方法实现多模态训练,让class-condition、text-to-image、layout-to-image等引导图像生成成为现实。上述开源的Stable Diffusion模型既是基于LDM算法训练所得。
三.未来,是否已经展开?
在AIGC这一领域,一种行业性的方向和难题在于,如何把现实中的一些新概念,或者说很难形容的物体,引入到生成过程中。技术语言将之称呼为Example based Generation。
Nvidia以训练一个新prompt从而适应新概念的方式,打造了Textual Inversion;Google则以Finetune LDM算法寻找原本模型中与新概念最相关的embedding,将之命名为DreamBooth。
而林倞与拓元智慧在这方面,有着探索与突破。其与中山大学联合推出的DreamAritist,以单个样例学习概念的方式解体,并且提出了Positive-negative prompt-tunning(正负双向提示)方法。

DreamAritist示例
Example based Generation所解决的问题,是将现实样例中抽象出的概念引入到生成阶段,让产出的内容从机械式的重复到创意的实现。
图像之外,视频内容生成技术,也已经有了实践。Tune-A-Video可以通过一个视频片段作为模型训练的样本,以Prompt控制生成类似的视频,再新增时空维度的cross-attention后,所生成的视频愈发丝滑
业内先行的Gen-1到Gen-2,就提出了基于文本描述或图像结构引导的隐视频扩散模型进行视频生成,且借助引导信息进行视频编辑。通过图像结构信息和内容本身,引入采样通道堆叠形式。
AIGC的另一关键,是Controllable Generation(可控生成)。其核心技术ControlNet是一种端到端的神经网络架构,以控制Stable Diffusion这类大型图像扩散模型的方式,学习特定任务,比如输入草稿后输出可控的高质量图像。
技术理论在于,将可训练和和锁定的神经网络块与“零卷积”的卷积层链接。零卷积的特点是,不会为深度特征添加新的噪声,相较从头开始训练的卷积层而言,训练速度与微调扩散模型一样迅速。
而基于ControlNet的AI作图实践,已经非常多。比如素描草稿图像形成、边缘检测图像形成等。但AI作图这类的AIGC技术,依旧存在局限性。内容的可控性依旧是无法忽视的大问题,视频与3D元素的生成还需要算法与底层技术的更新,通用视觉大模型、提示/适配的技术难度与复杂度都极高。最为关键的是,商业模式还需要验证。
要了解目前的AIGC技术,就必须看到目前预训练大模型的局限性。理想中的模型,应该是具备强解释性、可泛化推广的“白盒”模型,而非尚未能解释、只能获得结果的“黑盒”。
四.拓元智慧的商业实践
拓元智慧的出现,本身是林倞为首的认知AI技术领域知名专家团队,共同的一次商业尝试。拓元智慧(X-Era AI)由顶尖AI技术团队创立,致力于运用自研多模态大模型、认知推理、因果模型等前沿AI技术,为用户提供可控内容生成及虚实交互解决方案。依托林倞教授创立领衔的中山大学人机物智能融合实验室(HCP Lab,在近期公布的CVPR2023入选15篇论文,核心成员还包含梁小丹、王可泽、李冠彬等知名AI青年科学家),拓元智慧持续创新,打通技术及业务闭环,目前已在IP数字分身、AI协同内容创作、企业数智服务等领域形成标化产品,服务知名客户百余家。
多模态认知AI的技术翻译,可以理解为以模拟人脑双通道理论为引导,所打造的计算模式、内容生成、虚实链接与交互的操作系统。使得AI同时具备人脑快思维与慢思维的“思考”能力。
作为操作系统,多模态认知AI引擎引入因果模型与心智模型,打造低成本多模态大模型为核心的AI引擎。这与主流AI商业化方案形成了差异性价值。目前常见的方案中,基本都以大数据、大模型与超级算力来解决感知层问题,成本高、场景数据缺失等问题普遍。而拓元智慧的解决方案,以自研技术核心框架,实现了灵活性与低成本的综合落地。
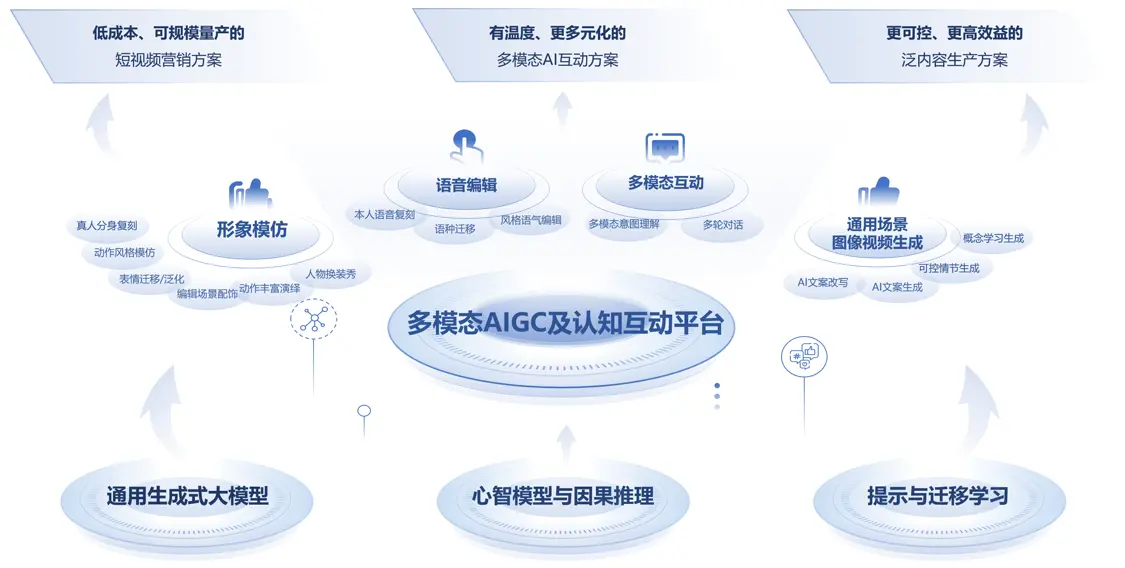
多模态认知AI平台示意图
其技术积累,可以分为三方面:
● 其一,低成本的大模型。可以实现小样本学习又可私有化部署。针对特定垂直场景,动态配置来满足客户成本、数据安全可控和能力灵活可扩展的核心诉求。
● 其二,大模型+因果图模型。可以打开想象与创造的空间。在大模型基础上引进因果推理模型和生成式算法,支撑可控、可泛化的生成效果。比如文案文本的一键裂变。又比如被林倞称为数字分身的“数智人”,完全可以实现人物、场景的自动编辑与创造。
● 其三,心智模型。提供个性化的交互与陪伴,在因果图模型基础上,赋予及其个性、价值观演进的能力,所产出的内容更具有灵性与温度。
技术的积累,外溢到了实际产品。拓元智慧的产品体系中,一个定位是能够革新内容创作形态的新一代AIGC平台,通过大模型创新可控生成式模型,融合因果推断与价值反馈激励,来拓展人类智慧与能力的边界。
其中已经落地的应用,是“元分身”。内容产业中,人物的视频拍摄与制作成本过高,是普遍痛点。结合AIGC的技术底座,拓元智慧打造了“元分身”作为第一款商用产品,以AI驱动真人数字分身,来实现对真人实拍的替代,实现视频生成优化、专家型交互等等,颠覆传统内容行业的效能瓶颈。
一个最直接的应用,是元分身可以支持使用标记剧本编导,让数智人演绎视频。无论是角色与镜头的转化,还是与语义关联的动作,甚至符合情景的情绪演绎,已经完全可以实现。而目前作为ChatGPT被热议话题的文案写作,拓元智慧的AI写手也能实现基于热点文案分析的裂变重构,完成用语、文法、文风的改写,一键生成裂变内容,可控又能全覆场景。
“未来或许就是元创作时代。”林倞表示,就目前AIGC技术的发展,多模态内容创作与编辑方式,已经发生了颠覆式变化。“我们在做的,是将技术底座开放给更多人,来构建生态。”
拓宽视野、引发思考、讨论碰撞、激发灵感。







- 暂时没有评论,来说点什么吧