

?【路径】大数据技术创新呈现“原创-开源-产品化”的阶梯格
大数据来源于互联网、企业系统和物联网等信息系统,经过大数据处理系统的分析挖掘,产生新的知识用以支撑决策或业务的自动智能化运转。从数据在信息系统中的生命周期看,大数据从数据源经过分析挖掘到最终获得价值一般需要经过 5 个主要环节,包括数据准备、数据存储与管理、计算处理、数据分析和知识展现,技术体系如图 1所示。每个环节都面临不同程度的技术上的挑战。 (一) 大数据对传统数据处理技术体系提出挑战 大数据来源于互联网、企业系统和物联网等信息系统,经过大数据处理系统的分析挖掘,产生新的知识用以支撑决策或业务的自动智能化运转。从数据在信息系统中的生命周期看,大数据从数据源经过分析挖掘到最终获得价值一般需要经过 5 个主要环节,包括数据准备、数据存储与管理、计算处理、数据分析和知识展现,技术体系如图 1所示。每个环节都面临不同程度的技术上的挑战。 数据准备环节:在进行存储和处理之前,需要对数据进行清洗、整理,传统数据处理体系中称为 ETL ( Extracting ,Transforming,Loading)过程。与以往数据分析相比,大数据的来源多种多样,包括企业内部数据库、互联网数据和物联网数据,不仅数量庞大、格式不一,质量也良莠不齐。这就要求数据准备环节一方面要规范格式,便于后续存储管理,另一方面要在尽可能保留原有语义的情况下去粗取精、消除噪声。 数据存储与管理环节:当前全球数据量正以每年超过 50%的速度增长,存储技术的成本和性能面临非常大的压力。大数据存储系统不仅需要以极低的成本存储海量数据,还要适应多样化的非结构化数据管理需求,具备数据格式上的可扩展性。 计算处理环节:需要根据处理的数据类型和分析目标,采用适当的算法模型,快速处理数据。海量数据处理要消耗大量的计算资源,对于传统单机或并行计算技术来说,速度、可扩展性和成本上都难以适应大数据计算分析的新需求。分而治之的分布式计算成为大数据的主流计算架构,但在一些特定场景下的实时性还需要大幅提升。 数据分析环节:数据分析环节需要从纷繁复杂的数据中发现规律提取新的知识,是大数据价值挖掘的关键。传统数据挖掘对象多是结构化、单一对象的小数据集,挖掘更侧重根据先验知识预先人工建立模型,然后依据既定模型进行分析。对于非结构化、多源异构的大数据集的分析,往往缺乏先验知识,很难建立显式的数学模型,这就需要发展更加智能的数据挖掘技术。 知识展现环节:在大数据服务于决策支撑场景下,以直观的方式将分析结果呈现给用户,是大数据分析的重要环节。如何让复杂的分析结果易于理解是主要挑战。在嵌入多业务中的闭环大数据应用中,一般是由机器根据算法直接应用分析结果而无需人工干预,这种场景下知识展现环节则不是必需的。大数据来源于互联网、企业系统和物联网等信息系统,经过大数据处理系统的分析挖掘,产生新的知识用以支撑决策或业务的自动智能化运转。从数据在信息系统中的生命周期看,大数据从数据源经过分析挖掘到最终获得价值一般需要经过 5 个主要环节,包括数据准备、数据存储与管理、计算处理、数据分析和知识展现,技术体系如图 1
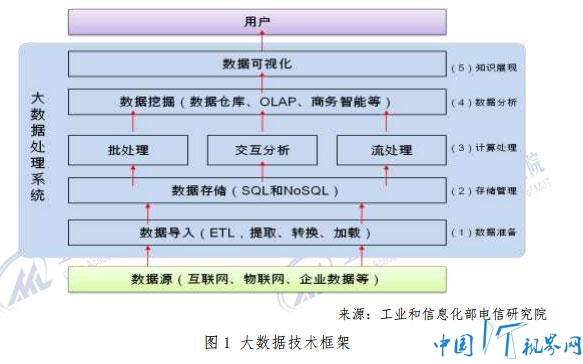
查看大图 总的来看,大数据对数据准备环节和知识展现环节来说只是量的变化,并不需要根本性的变革。但大数据对数据分析、计算和存储三个环节影响较大,需要对技术架构和算法进行重构,是当前和未来一段时间大数据技术创新的焦点。下面简要分析上述 3 个环节面临的挑战及发展趋势。 (二) 大数据存储、计算和分析技术是关键 1.大数据存储管理技术 数据的海量化和快增长特征是大数据对存储技术提出的首要挑战。这要求底层硬件架构和文件系统在性价比上要大大高于传统技术,并能够弹性扩展存储容量。但以往网络附着存储系统(NAS)和存储区域网络(SAN)等体系,存储和计算的物理设备分离,它们之间要通过网络接口连接,这导致在进行数据密集型计算(Data Intensive Computing)时 I/O 容易成为瓶颈。同时,传统的单机文件系统(如NTFS)和网络文件系统(如 NFS)要求一个文件系统的数据必须存储在一台物理机器上,且不提供数据冗余性,可扩展性、容错能力和并发读写能力难以满足大数据需求。 谷歌文件系统(GFS)和 Hadoop 的分布式文件系统 HDFS(Hadoop Distributed File System)奠定了大数据存储技术的基础。与传统系统相比,GFS/HDFS 将计算和存储节点在物理上结合在一起,从而避免在数据密集计算中易形成的 I/O 吞吐量的制约,同时这类分布式存储系统的文件系统也采用了分布式架构,能达到较高的并发访问能力。存储架构的变化如图 2 所示。 当前随着应用范围不断扩展,GFS 和 HDFS 也面临瓶颈。虽然 GFS和 HDFS 在大文件的追加(Append)写入和读取时能够获得很高的性能,但随机访问(random access)、海量小文件的频繁写入性能较低,因此其适用范围受限。业界当前和下一步的研究重点主要是在硬件上基于 SSD 等新型存储介质的存储体系架构,同时对现有分布式存储的文件系统进行改进,以提高随机访问、海量小文件存取等性能。

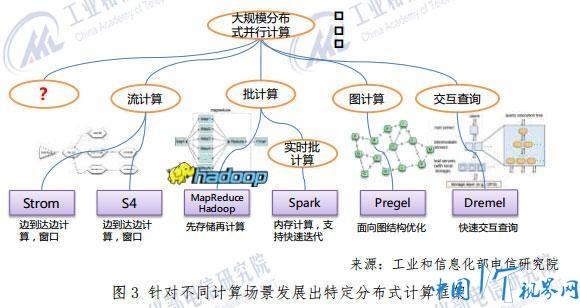
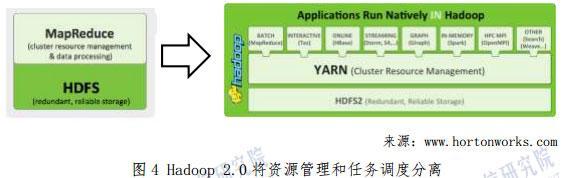
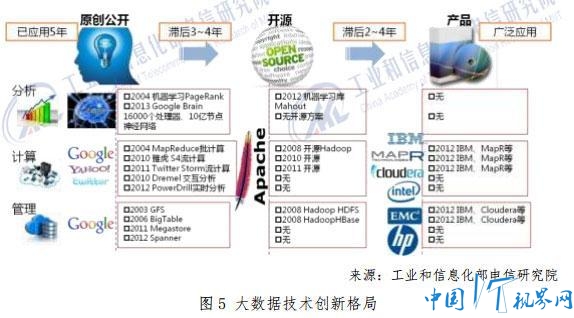
查看大图 总结互联网企业在大数据技术创新方面的经验,如下几个方面值得关注: 第一,丰富的数据和强大的平台是大数据创新的基础条件。以谷歌为例,它的数据资源极为丰富,拥有全球网页索引库,掌握几十亿用户的搜索行为数据,建立了高分辨率的谷歌地图数据数据库,拥有2014谷歌+社交数据和 YouTube 海量视频数据。谷歌的基础设施也十分强大,在全球拥有 36 个超大型数据中心,上百万台服务器。 第二,大数据的应用效益不是飞跃突进的,必须依靠长期的不断累积。从搜索、广告和推荐等成熟应用来看,大数据的应用效果并非立竿见影,其巨大的效益是在日积月累的微小进步中逐渐形成的。 第三,累积效益的获取,主要靠持续不断的技术迭代。互联网企业一直奉行敏捷开发、快速迭代的软件开发理念,往往在一两周内就能完成一个“规划、开发、测试、发布”的迭代周期。大型互联网企业通过这种长期持续“小步快跑”的研发方式,支撑了大数据应用效果的持续提升,建立了技术上的领先优势。 第四,技术和应用一体化组织,是快速迭代的保障。互联网企业之所以能够保持高效率的持续技术演进,其研发和应用一体化的组织方式是很重要的因素。与传统行业“应用者——解决方案提供商”分离的组织形态不同,互联网企业省去了解决方案供应商环节,可以迅速将需求转化为解决方案。谷歌、百度等大型互联网企业的研发人员占比一般都在 50%∼70%,远远高于其他类型的公司,这为技术开发提供了强大的后盾。 最后,大数据技术发展与开源运动的结合也成为大数据技术创新中的一个鲜明特点。领先企业进行前沿创新,创新成果通过开源得到不断完善并向全社会辐射,原创与开源相得益彰,在国际上形成了一套高效运转的研发产业化体系。开源模式让人们“不必重复发明轮子”,能够降低研发和采购成本,还能够启发新的创意,加快再创新步伐。特别是开源 Apache Hadoop 的大范围应用,大大加速了大数据应用进程,一大批互联网公司和传统 IT 企业都从这种技术扩散体系中受益。在此背景下,国内大数据技术研发也应该把自主创新和开源结合起来,以更加开放的心态融入到国际大数据技术创新潮流中去。 如果您认为该文章不错,请转发至朋友圈。分享知识,分享快乐!







评论
- 暂时没有评论,来说点什么吧